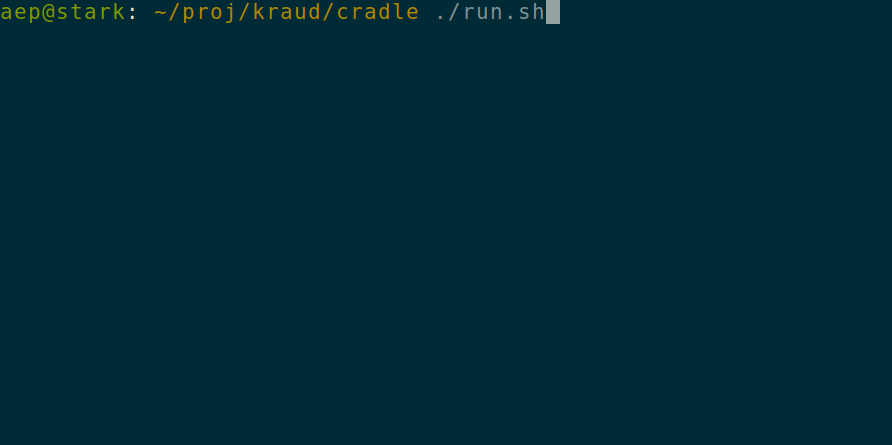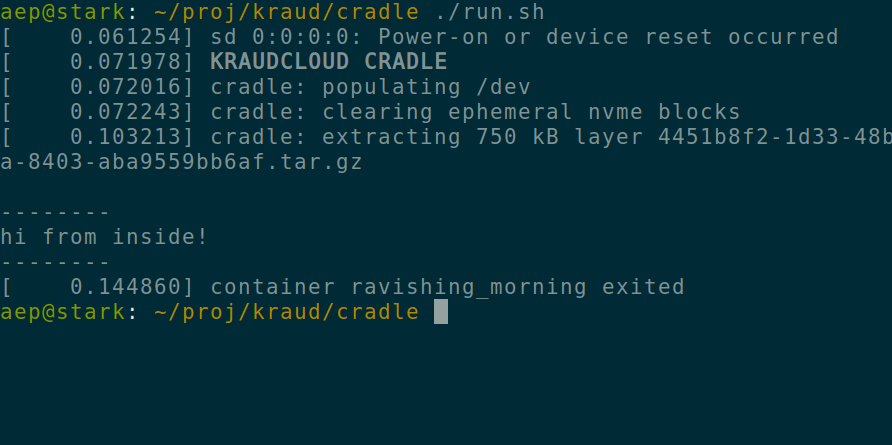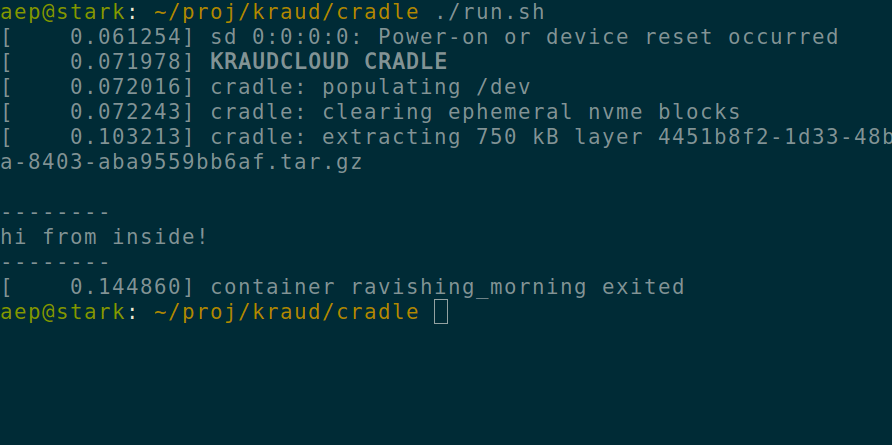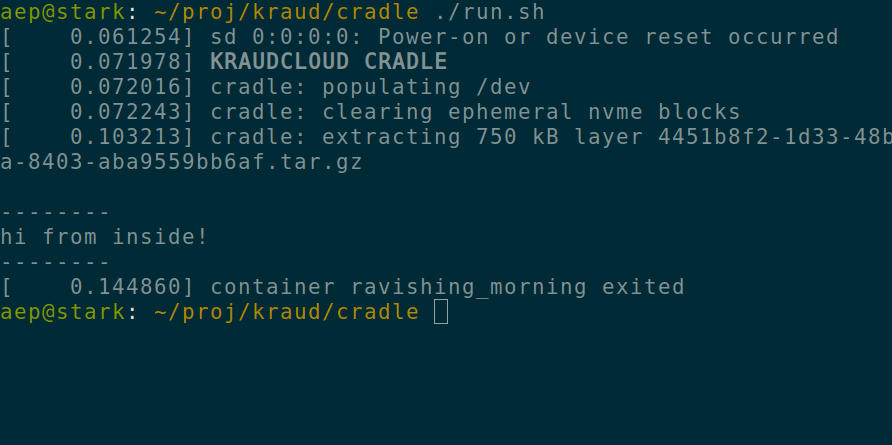
exclusive worker tokens with NATS
At kraud we of course use several orchestration engines. During the process or retiring Hashicorp Nomad, a few new exciting things are created that i hope to open source soon.
The core of it is a bunch of workers, and items to be worked on. A fairly standard work queue situation. Currently everything is built around notifying a worker through redis, and then holding a lock in redis for that particular resource. Redis is doing a great job at all of that, but somehow i felt like exploring the new(ish) thing for reliable notifications: nats.io's jetstream and then realized that nats can now also do locks!
locking with nats.io
the maintainers comment here describes the solution to building a lock with NATS.
The idea is to have a stream with DiscardNewPerSubject, which prevents new items being published to a key already holding a value.
in a distributed system you would also have to think about expiry and refreshing, which would be done with with the MaxAge stream setting. but then exactly what i hoped for had happened: i discovered an entirely new method of building workers in the design of nats.
exclusive work tokens
in addition to locks, you would also have to notify a worker that new work is available, something trivially done in either redis or nats although i feel like nats has a slight edge here because it can actually guarantee that a message is delivered with jetstream, which simplifies retry on the application side.
But what if we just notified one worker and then made sure to not notify any other worker until the first one is done. That's essentially a classic token ring,bus,whatever architecture where a token is handed around that makes the holder eligible for accessing a shared resource.
We already have that thing in the previous step. Just have to use it the other way around.
the first difference is retention=work, which says that any acked message is discarded. since we only allow one item per subject , this means the subject is blocked until it is acked.
now instead of locking an item from the worker, we push the work into the subject from the requester
workers then consume work items
nats will deliver the message to only one random worker. If the worker fails to ack the work in time, it is redelivered again to a random worker until an ack finally clears the message. Since we only allow one message per subject to be queued, this means only one worker will ever work on it. Of course the worker can receive work on other subjects in the meantime, just not on this one.
In this cli example the timeout is fixed, and the worker cannot really tell nats to hold back redelivery until its done, but i'll get to a full code example in a second where it can.
but queueing?
Most of the time you just want to set-and-forget work items into a queue and not wait for the workers to be available. nats has enother elegant construct we can use for that: sources
We can just have another stream that allows more than one message per subject
and then create the work stream with that one as source
now publishing multiple work items on the same subject is allowed
yet, only one will be actually worked on at a time
once the item in work is acked, nats will automatically feed the next one.
implementation in go
now as promised, here's a complete example in golang including the ability to hold an item in the queue for longer than its ack timeout.